LLM-Modellformate, Konvertierung und Quantisierung
15. Dez. 2025
Ich habe verschiedene Arten von KI-Modellen getestet und damit experimentiert, darunter Stable Diffusion (SD) und Large Language Models (LLMs). Aufgrund meiner begrenzten Rechenkapazitäten (mit insgesamt 96 GB GPU-Speicher) kann ich nicht alle verfügbaren Modelle nativ ausführen. Insbesondere die neuesten LLMs (Stand Dezember 2025) sind für meine Hardware zu groß. Daher mussten verschiedene quantisierte Versionen ausgeführt werden. Da die Auswahl an verfügbaren Modellformaten und Quantisierungsoptionen erheblich gewachsen ist, fasse ich in diesem Beitrag meine Erkenntnisse zusammen (vielleicht ist das für jemanden nützlich).
Modelldateiformate
Die fünf Modelldateiformate, denen ich am häufigsten begegnet bin, sind:
bin: Old-School-Allrounderpt: Das native Format von PyTorchsafetensors: Sicher, schnell und Framework unabhängigggml: Leichtgewichtiges, CPU-freundliches Format (alteslama.cpp-Format)gguf: Das moderne llama.cpp-Format (Nachfolger vonggml)
In diesem Abschnitt fasse ich den Hintergrund dieser Formate zusammen.
bin: Old-School Catch-All
Obwohl bin technisch gesehen kein Format ist, handelt es sich dennoch um eine Art der Modelldarstellung, die typisch für frühere Versionen älterer Transformer-Modelle ist. Aufgrund seines generischen Formats konnten Frameworks wie PyTorch oder TensorFlow (je nach Herkunft) ihre Modellgewichte als bin speichern.
Schließlich bedeutet die Erweiterung bin einfach „Binärdatei“ und wurde in der Vergangenheit als generischer Container für Modellgewichte verwendet.
Obwohl dieses Format nach wie vor verbreitet ist und weitreichende Unterstützung findet, da es das Speichern und Laden von Modellgewichten vereinfacht, erfordert es für die Speicherung eine beträchtliche Menge an Speicherplatz. Außerdem verfügt es über keine integrierten Sicherheitsgarantien und keine Standardstruktur (was bedeutet, dass zwei „bin“-Dateien inhaltlich völlig unterschiedlich sein können).
Daher wird es hauptsächlich für ältere Modelle oder schnelle manuelle Checkpoints verwendet. Moderne Arbeitsabläufe bevorzugen strukturiertere Formate.
pt: Das native Format von PyTorch
pt ist typisch für die Training-Pipelines von PyTorch und das offizielle Speicherformat für Modelle unter PyTorch, das zum Speichern folgender Daten verwendet wird:
- Modellgewichte,
- Optimiererzustände und
- vollständige Training-Checkpoints.
Es beruht auf Python pickle, und manchmal werden Dateien auch als pth gespeichert. Daher ist dieses Format ein offizielles Format, das vollständig mit PyTorch kompatibel ist und den vollständigen Trainingsstatus darstellt (sofern es so gespeichert wurde). Da es jedoch pickle verwendet, ermöglicht es auch die Ausführung von beliebigem Code, was bedeutet, dass es nicht sicher ist, es aus nicht vertrauenswürdigen Quellen zu laden. Ähnlich wie bin kann pt groß sein und langsam laden.
Daher wird pt hauptsächlich für das Training von Modellen, die Erstellung von Forschungsprototypen oder den Austausch von Checkpoints zwischen PyTorch-Teams verwendet.
safetensors: Sicher, Schnell und Framework Unabhängig
Das safetensors-Format wurde vom Team von Hugging Face entwickelt und ist ein Format, das typischerweise von Diffusionsmodellen, LLMs und allen öffentlich geteilten Modellen verwendet wird. Im Gegensatz zu pt wird das safetensors-Format von einer größeren Vielfalt an Frameworks wie PyTorch, TensorFlow, JAX usw. unterstützt.
Daher kann man sagen, dass safetensors eine moderne Alternative zu pt ist und auf zwei Ziele ausgerichtet ist:
- Sicherheit (kein Pickle, kein ausführbarer Inhalt, 100 % sicher beim Laden aus nicht vertrauenswürdigen Quellen)
- Geschwindigkeit (Zero-Copy-Speicherzuordnung, schnelleres Laden als
pt)
Allerdings ist das safetensors-Format im Vergleich etwas starrer, was bedeutet, dass es nicht so mühelos für exotische (bzw. selbst definierte) Checkpoint-Strukturen verwendet werden kann.
Daher wird es hauptsächlich beim Herunterladen von Modellen aus dem Internet, beim sicheren Verteilen von Modellen oder beim Ausführen großer Modelle mit hoher Leistung verwendet.
ggml: Leichtgewichtiges, CPU-freundliches Format
Das ggml-Format wurde von Georgi Gerganov (für llama.cpp) entwickelt und ist für CPU- und Small-Device-Inferenz optimiert. Es unterstützt quantisierte Modelle (4-Bit, 5-Bit, 8-Bit), wodurch die Dateigrößen reduziert werden können. Die Abkürzung steht daher für Georgi Gerganov Machine Learning.
Ich würde sagen, dass ggml das bahnbrechende Format war, da es die lokale Ausführung von Modellen im LLaMA-Stil auf Laptops und sogar Smartphones ermöglichte. Heutzutage werden LLMs oft quantisiert, um die Größe und den Speicherverbrauch drastisch zu reduzieren.
Das Format ggml ist jedoch mittlerweile veraltet und nicht standardisiert. Es lässt sich zwar schneller laden als bin, pt oder safetensors, aber immer noch langsamer als Nachfolgemodelle (wie gguf).
Daher wird ggml meist für ältere Versionen von llama.cpp oder Legacy-Modelle verwendet.
gguf: Das moderne llama.cpp Format
Laut den Betreuern von llama.cpp steht gguf für GPT-Generated Unified Format (manchmal auch als GGML Unified Format erklärt). Es ist hinsichtlich Geschwindigkeit, Metadaten, Quantisierung und Portabilität optimiert.
Daher ist gguf das neue empfohlene Format für das llama.cpp-Ökosystem. Es behebt viele Einschränkungen von ggml und bietet umfangreiche Metadaten, eine verbesserte Ladegeschwindigkeit und eine breite Tool-Unterstützung.
Allerdings hat auch gguf seine Nachteile. Beispielsweise ist es für ältere Frameworks nicht lesbar und erfordert eine Modellkonvertierung aus den ursprünglichen Gewichten.
Dennoch hat sich gguf als neuer Standard durchgesetzt und ermöglicht die Ausführung quantisierter LLMs auf Heim-PCs (einschließlich Raspberry Pi) und ist mit lokalen Inferenzengines (z. B. Ollama, llama.cpp, LM Studio, KoboldCpp usw.) kompatibel.
Weitere erwähnenswerte Formate
Obwohl ich sie nicht verwendet habe, gibt es auch andere Formate, die erwähnenswert sein könnten.
ONNX (.onnx)
Dies ist ein frameworkübergreifendes, portables Format, das von PyTorch, TensorFlow, C++, JavaScript usw. unterstützt wird. Es ist beliebt für Produktionsbereitstellungen und die Optimierung von Modellen für die Inferenz (z. B. ONNX Runtime).
H5 (.h5 / .hdf5)
Dies ist das ältere Keras/TensorFlow-Format. Es verliert zwar an Popularität, wird aber immer noch in älteren Projekten verwendet.
.ckpt
Dies ist eine generische Checkpoint-Datei, die frameworkübergreifend verwendet wird, aber nicht standardisiert ist. Sie ist in älteren Stable Diffusion-Modellen weit verbreitet, aber diese haben aufgrund ihrer Vorteile auch safetensors übernommen.
Zusammenfassung der Modellformate
Jedes dieser Dateiformate spiegelt einen Moment in der Entwicklung der Machine-Learning-Praxis wider:
- Bei trainingsintensiver Forschung verwendet man
pt - Bei der öffentlichen Freigabe von Modellen verwendet mab
safetensors - Wenn Sie eine effiziente lokale Inferenz wünschen, verwendet man
ggmloder (vorzugsweise)gguf
Quantisierung
Sowohl ggml als auch gguf unterstützen die Quantisierung von Modellen. Bei der Quantisierung werden die Datentypen, in denen die Modellgewichte gespeichert sind, in weniger präzise Datentypen umgewandelt, um den Speicherbedarf beim Speichern des Modells zu reduzieren. Es handelt sich also um einen Kompromiss zwischen Modellgeschwindigkeit, -größe und -genauigkeit.
Während Modelle in voller Größe in der Regel Fließkommadarstellungen verwenden (d.h. F16 für 16-Bit-Fließkommawerte oder F32 für 32-Bit-Fließkommawerte), reduziert die Quantisierung die Genauigkeit durch die Verwendung kleinerer Darstellungen. Die Suffixe der Modelldateien (Q4_K_M, Q6_K oder Q8_0) geben Aufschluss darüber, wie anspruchsvoll oder leistungsfähig das Modell ist.
Das Suffix kann in vier Teile unterteilt werden:
- Verbesserte Quantisierung: Das Präfix
Isteht für einen ganzzahligen oder verbesserten Quantisierer. - Quantisierungsstufe:
Qgefolgt von einer Ziffer (z. B.Q4,Q6,Q8usw.), die die Anzahl der Bits in jedem quantisierten Gewichtsspeicher angibt. - Das Quantisierungsformat:
Ksteht für gruppierte Quantisierung (verwendet Skala und Nullpunkt pro Gruppe),0steht für ungruppiert (Quantisierung im älteren Stil) und1steht für ein anderes älteres Quantisierungsformat. - Die Quantisierungsgenauigkeit:
Sfür geringe Genauigkeit (am schnellsten, geringere Genauigkeit),Mfür mittlere Genauigkeit oderLfür hohe Genauigkeit (am langsamsten, höhere Genauigkeit).
Das bedeutet, dass das Beispiel Q4_K_M ein quantisiertes Modell mit 4 Bits pro Gewicht einer Variante mittlerer Genauigkeit/Qualität des K-Schemas ist.
Der Quantisierungsprozess wandelt nicht einfach Fließkommawerte in ganzzahlige Darstellungen um (hier würde ein Wert von 0,327 auf 0 gerundet werden), da Modellgewichte in der Regel nahe Null liegen und nicht den gesamten Bereich der Ganzzahlen nutzen (z. B. 0 bis 255 einer vorzeichenlosen 8-Bit-Ganzzahl). Daher werden eine Skala \(d\) und ein Nullpunktversatz \(m\) verwendet, um den Bereich des von der Quantisierung verwendeten Datentyps optimal zu nutzen:
\[ w = d \cdot q + m\]
Bei der Wiederherstellung des Gewichts \(w\) aus dem quantisierten Wert \(q\) liegt das Ergebnis nahe am ursprünglichen Wert, entspricht jedoch nicht genau diesem. Für die meisten Anwendungen ist dieser Quantisierungsverlust jedoch akzeptabel.
Modellperplexität
Es ist möglich zu messen, inwieweit die Quantisierung die Modellgenauigkeit beeinträchtigt. Die Metrik, die dies tut, wird als Perplexität bezeichnet. Die Perplexität misst, wie gut ein Sprachmodell Text vorhersagt. Eine niedrigere Perplexität bedeutet weniger "Verwirrung" des Modells und ein Verhalten, das näher an der Originalversion ohne Quantisierung liegt. Beim Vergleich von Quantisierungsschemata ist vor allem die relative Perplexität wichtig, d.h. die Perplexität des quantisierten Modells im Vergleich zu seinem Gegenstück mit voller Genauigkeit FP16 oder FP32. Wenn Sie ./llama-quantize --help im Projekt llama.cpp ausführen, wird eine Tabelle mit allen unterstützten Quantisierungsvarianten und ihren Perplexitywerten angezeigt (die Zahlen basieren auf dem Vicuna-13B-Modell):
Allowed quantization types:
2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B
3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B
38 or MXFP4_MOE : MXFP4 MoE
8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B
9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
28 or IQ2_S : 2.5 bpw quantization
29 or IQ2_M : 2.7 bpw quantization
24 or IQ1_S : 1.56 bpw quantization
31 or IQ1_M : 1.75 bpw quantization
36 or TQ1_0 : 1.69 bpw ternarization
37 or TQ2_0 : 2.06 bpw ternarization
10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B
21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B
23 or IQ3_XXS : 3.06 bpw quantization
26 or IQ3_S : 3.44 bpw quantization
27 or IQ3_M : 3.66 bpw quantization mix
12 or Q3_K : alias for Q3_K_M
22 or IQ3_XS : 3.3 bpw quantization
11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B
12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B
13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B
25 or IQ4_NL : 4.50 bpw non-linear quantization
30 or IQ4_XS : 4.25 bpw non-linear quantization
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B
15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B
17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B
18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B
7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B
1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B
32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B
0 or F32 : 26.00G @ 7BWie hier auf Github erläutert, ändert sich die Perplexität je nach Größe des Modells oder Wahl der Quantisierung:
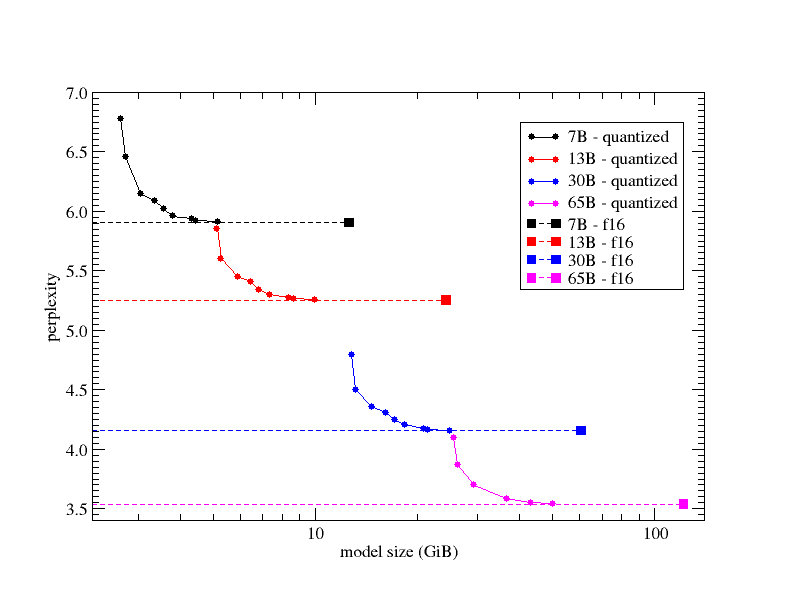
Es ist zu beachten, dass die x-Achse (Modellgröße in GiB) logarithmisch ist. Die verschiedenen Kreise im Diagramm zeigen die Perplexität verschiedener Quantisierungsmischungen, und die ausgefüllten Quadrate stehen für das ursprüngliche FP16-Modell (d.h., für jede Zeile wurde Q2_K → Q3_K → Q4_K → Q5_K → Q6_K → Q7_K → FP16 verwendet). Die verschiedenen Farben geben die verwendete LLaMA-Variante an (7B in Schwarz, 13B in Rot, 30B in Blau, 65B in Magenta). Die gestrichelten Linien wurden der Übersichtlichkeit halber hinzugefügt, um besser beurteilen zu können, wie nahe die quantisierten Modelle an die „FP16“-Perplexität herankommen. Wie aus diesem Diagramm ersichtlich ist, ist die Generierungsleistung, gemessen anhand der Perplexität, im Grunde eine ziemlich gleichmäßige Funktion der Größe des quantisierten Modells, und die Quantisierungstypen ermöglichen es dem Benutzer, das quantisierte Modell mit der besten Leistung auszuwählen, unter Berücksichtigung der Grenzen seiner Rechenressourcen (im Hinblick auf die Möglichkeit, das Modell vollständig in den Speicher zu laden, aber auch im Hinblick auf die Inferenzgeschwindigkeit, die in der Regel von der Modellgröße abhängt).
Bemerkenswert ist vielleicht, dass die Perplexität des 6-Bit-quantisierten Modells (Q6_K) innerhalb von 0,1 % oder besser vom ursprünglichen FP16-Modell liegt.
Modelle Konvertieren
Manchmal werden Modelle auf Hugging Face in einem Rohformat bereitgestellt, das für die lokale Ausführung zu groß ist. Daher ist es notwendig, das Modell von einem Format in ein anderes zu konvertieren. Der Konvertierungsprozess umfasst:
- das Abrufen der ursprünglichen Gewichte,
- das Laden dieser Gewichte in Python und
- das Exportieren dieser Gewichte mithilfe eines Konvertierungsskripts.
Hier ist llama.cpp mein bevorzugtes Tool geworden, und im folgenden Abschnitt erkläre ich, wie man Modelle mit llama.cpp konvertiert.
Modell erhalten
Typischerweise sieht ein Hugging Face-Modellordner in etwa so aus:
model/
config.json
tokenizer.json / tokenizer.model / vocab files
model-00001-of-00004.safetensors
model-00002-of-00004.safetensors
model-00003-of-00004.safetensors
model-00004-of-00004.safetensorsHändisch
Am einfachsten ist es, das Modell über einen Browser herunterzuladen, indem Sie https://huggingface.co/models aufrufen, das gewünschte Modell auswählen, auf files and versions klicken und jede Datei des Modells manuell herunterladen. Bei größeren Modellen kann dies recht mühsam sein.
Git LFS
Alternativ kann Git LFS (Large File System) verwendet werden. Dazu muss LFS installiert werden:
git lfs installAnschließend kann das Modell-Repository geklont werden:
git clone https://huggingface.co/<user>/<model-name>Dadurch werden alle Dateien des Modells automatisch heruntergeladen.
Hugging Face CLI
Wenn man sich anmeldet, um ein Modell herunterzuladen, kann man die Hugging Face CLI verwenden, um das Modell-Repository automatisch herunterzuladen. Das CLI kann wie folgt installiert werden:
pip install huggingface_hubDann muss man sich mit folgenden Daten anmelden:
huggingface-cli loginUnd schließlich kann das Repository wie folgt heruntergeladen werden:
huggingface-cli download <user>/<model-name> --local-dir ./modelKonvertierung
Verwendung des geladenen Repository
Zunächst muss der Konverter (z.B. llama.cpp) beschafft werden. Für gguf ist die am häufigsten verwendete Toolchain llama.cpp, die wie folgt heruntergeladen und eingerichtet werden kann:
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
# if you want to use the Python converter
pip install -r requirements.txt
# if you want to quantize and/or run models
cmake -B build
cmake --build build --config ReleaseDas Konvertierungsskript kann wie folgt ausgeführt werden:
python3 convert_hf_to_gguf.py \
/path/to/model \
--outfile /path/to/output/model.gguf \
--vocab-type autoHier ist /path/to/model der Ordner, der Folgendes enthält:
config.json- Tokenizer-Dateien
- mehrere
safetensors-Dateien
Das Skript lädt dann automatisch die Konfiguration, liest alle safetensor-Shards, führt sie zusammen und schreibt eine Fließkomma-gguf-Datei.
Zu diesem Zeitpunkt wurde eine „Basis“-gguf-Datei erstellt (oft f16), die (je nach Modell) sehr groß sein kann.
Um kleinere Dateien zu erhalten (z.B. Q4_K_M, Q5_0 usw.), muss man quantisieren:
./llama-quantize \
/path/to/output/model.gguf \
/path/to/output/model-Q4_K_M.gguf \
Q4_K_MDocker
Alternativ kann man das offizielle Docker-Image herunterladen, wodurch die händische Installation von Abhängigkeiten entfällt:
docker pull ghcr.io/ggml-org/llama.cpp:fullEinen Docker-Container kann dann wie folgt gestartet werden und dann können dieselben Befehle wie oben verwenden werden.
docker run --rm -it \
-v $HOME/llama-models:/models \
--entrypoint /bin/bash \
ghcr.io/ggml-org/llama.cpp:fullAlternativ kann man auch nur die Konvertierungs-/Quantisierungsbefehle mit Docker ausführen:
docker run --rm -it \
-v $HOME/llama-models:/models \
ghcr.io/ggml-org/llama.cpp:full \
--convert /models \
--outfile OUTFILE \
--outtype OUTTYPEHier ist der Parameter /models das Verzeichnis, das die Modelldatei enthält (es kann durch eine Huggingface-Repository-ID ersetzt werden, wenn das Modell noch nicht heruntergeladen wurde). Der Parameter OUTFILE (optional) ist der Pfad, in den das konvertierte/quantisierte Modell geschrieben wird (Standard ist basierend auf dem Eingabeverzeichnis). Der Parameter OUTTYPE (optional) gibt das Ausgabeformat des Modells an und kann sein:
f32fürfloat32,f16fürfloat16,bf16fürbfloat16,q8_0fürQ8_0,tq1_0odertq2_0für ternär, undautofür den 16-Bit-Float-Typ mit der höchsten Genauigkeit, abhängig vom zuerst geladenen Tensor-Typ.
Weitere Informationen zu llama.cpp und seinem Docker-Image finden Sie hier.