Claude Code Lokal
20. Mai. 2026
Claude Code ist vor allem als Coding-Agent für Anthropic-Modelle bekannt. In VS Code lässt sich Claude Code direkt über eine Extension verwenden. Sie bietet ein Chat-Panel, eine Diff-Ansicht, einen Plan-Modus, Datei-Referenzen und Zugriff auf die Claude-Code-CLI im integrierten Terminal. Die Extension bringt die CLI mit und teilt sich viele Einstellungen mit ihr.
Spannend wird es, wenn man Claude Code nicht mit einem Cloud-Modell, sondern mit einem lokal gehosteten LLM verwenden möchte. Genau das ist inzwischen mit Ollama möglich. Ollama stellt eine Anthropic-kompatible Messages API bereit, über die Tools wie Claude Code lokale oder über Ollama verfügbare Modelle ansprechen können.
In diesem Beitrag erläutere ich: was der Grund sein kann, warum man lokal gehostete LLMs überhaupt verwenden mag; wie man grundsätzlich Claude Code anweist, mit Ollama zu kommunizieren; und wie man dies in VS Code umsetzt.
Warum lokale Modelle?
Lokale LLMs sind besonders interessant, wenn man:
- Code nicht an externe APIs senden möchte,
- ohne nutzungsbasierte Tokenkosten experimentieren will,
- verschiedene Open-Source-Modelle für Coding-Aufgaben testen möchte,
- offline oder in kontrollierten Entwicklungsumgebungen arbeiten will.
Natürlich gibt es Grenzen! Lokale Modelle brauchen ausreichend Rechen- und Grafikkartenspeicher, sind je nach Modell langsamer als Cloud-Modelle und erreichen nicht immer die Qualität der größten proprietären Modelle. Für viele Coding-Workflows reicht ein gutes lokales Modell aber erstaunlich weit; insbesondere, da die neuesten Modelle eine Kontextlänge von 256K haben und auf handelsüblicher Hardware betrieben werden können.
Grundidee: Claude Code spricht mit Ollama statt mit Anthropic
Claude Code erwartet normalerweise eine Anthropic-API. Ollama bietet dafür inzwischen eine kompatible Schnittstelle unter dem lokalen Ollama-Server an. Statt Anfragen an api.anthropic.com zu schicken, setzt man in Claude Code einfach eine andere Base-URL:
export ANTHROPIC_AUTH_TOKEN=ollama
export ANTHROPIC_BASE_URL=http://localhost:11434Sollte der Ollama-Server nicht auf demselben Gerät betrieben werden, kann man auch anstelle von http://localhost:11434 die entsprechende IP-Adresse zum Ollama-Server eingeben. Die Variable ANTHROPIC_AUTH_TOKEN wird von Claude Code zwar erwartet, von Ollama aber nicht wirklich validiert. Ollama dokumentiert genau diese Konfiguration für Tools, die eine Anthropic-kompatible API erwarten.
Implementierung in VS Code
Für die Implementierung dieser Grundidee in VS Code braucht man:
- VS Code: Die Entwicklungsumgebung kann von hier heruntergeladen und installiert werden.
- Claude Code / Claude-Code-Extension: Danach muss die Extension über den VS-Code-Extension-Marketplace installiert werden, indem man nach "Claude Code" sucht. Wie die Claude Code Extension dann mit Ollama in Verbindung gesetzt werden kann, wird unten im Detail erläutert.
- Ollama: Wie Ollama installiert bzw. ein Ollama-Server über Docker bereitgestellt werden kann, wird unten im Detail erläutert
- Ein geeignetes Modell: Für Coding-Aufgaben empfiehlt Ollama unter anderem Modelle wie qwen3-coder, qwen3-coder-next, qwen3.6, qwen3.5, oder glm-4.7; aber auch die Verwendung von Cloud-Modelle wie glm-5.1:cloud und kimi-k2.6:cloud is möglich.
Claude Code Extension mit Ollama verbinden
Variante 1: Der einfachste Weg
Der einfachste Weg ist der neue Ollama-Shortcut:
ollama launch claudeOllama startet dann einen geführten Setup-Prozess, in dem ein Modell ausgewählt werden kann. Laut Ollama wird Claude Code dabei automatisch konfiguriert und gestartet. Beispielsweise mit einem bestimmten Modell:
ollama launch claude --model qwen3.5Oder für ein Cloud-Modell über Ollama:
ollama launch claude --model glm-5:cloudDiese Variante ist ideal, wenn man erst einmal testen möchte, ob Claude Code grundsätzlich mit Ollama funktioniert.
Variante 2: Einstellungen in VS Code vornehmen
Für ein dauerhaftes Setup ist die manuelle Konfiguration oft besser nachvollziehbar. Zuerst ein Modell herunterladen:
ollama pull qwen3-coderDann Claude Code mit Ollama starten:
ANTHROPIC_AUTH_TOKEN=ollama \
ANTHROPIC_BASE_URL=http://localhost:11434 \
claude --model qwen3-coderOllama zeigt in seiner Dokumentation genau dieses Muster für Claude Code. Hierbei zeigt die Variable ANTHROPIC_BASE_URL auf den lokalen Ollama-Server, und claude --model ... wählt das Modell aus.
Die VS-Code-Extension und die CLI teilen sich zentrale Claude-Code-Einstellungen. Anthropic beschreibt, dass Claude Code Einstellungen unter anderem in ~/.claude/settings.json liest und dass die Extension diese Claude-Code-Konfiguration ebenfalls verwendet. Damit VS Code nicht davon abhängt, ob es aus einer Shell mit den richtigen Umgebungsvariablen gestartet wurde, können die Variablen direkt in ~/.claude/settings.json hinterlegt werden:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "ollama",
"ANTHROPIC_BASE_URL": "http://localhost:11434",
"ANTHROPIC_API_KEY": ""
}
}Anthropic dokumentiert, dass Variablen im env-Block der Settings-Datei beim Start von Claude Code gelesen werden und unabhängig davon wirken, wie claude gestartet wurde.
Danach:
- Ollama starten.
- VS Code mit der Claude-Code-Extension öffnen.
- Als Modell ein Ollama-Modell verwenden, (zum Beispiel
claude --model qwen3-coder) oder im Claude-Code-Panel beziehungsweise über die Modell-Auswahl ein entsprechendes Modell setzen, falls es angeboten wird.
Alternativ kann man auch die Einstellung der Extension selbst in VS Code ändern, indem folgender Eintrag der Datei settings.json für die Benutzereinstellungen hinzugefügt wird:
...
"claudeCode.environmentVariables": [
{ "name": "ANTHROPIC_API_KEY", "value": "" },
{ "name": "ANTHROPIC_BASE_URL", "value": "http://localhost:11434" },
{ "name": "CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC", "value": "1" }
],
...Modellauswahl leicht gemacht
Möchte man schnell zwischen Modellen wechseln, kann man diese auch in der settings.json Datei hinterlegen:
...
{ "name": "ANTHROPIC_MODEL", "value": "qwen3.5:9b" },
{ "name": "ANTHROPIC_DEFAULT_SONNET_MODEL", "value": "qwen3.5:27b" },
{ "name": "ANTHROPIC_DEFAULT_OPUS_MODEL", "value": "qwen3-coder:30b" },
{ "name": "ANTHROPIC_DEFAULT_HAIKU_MODEL", "value": "qwen3-coder-next:latest" },
...Die Variable ANTHROPIC_MODEL setzt das Default-Modell fest, das die Claude Code Extension verwenden soll, und wechselt man im Prompt die Modelle, werden anstelle der Modelle von Anthropic die in Ollama zur Verfügung stehenden Modelle verwendet.
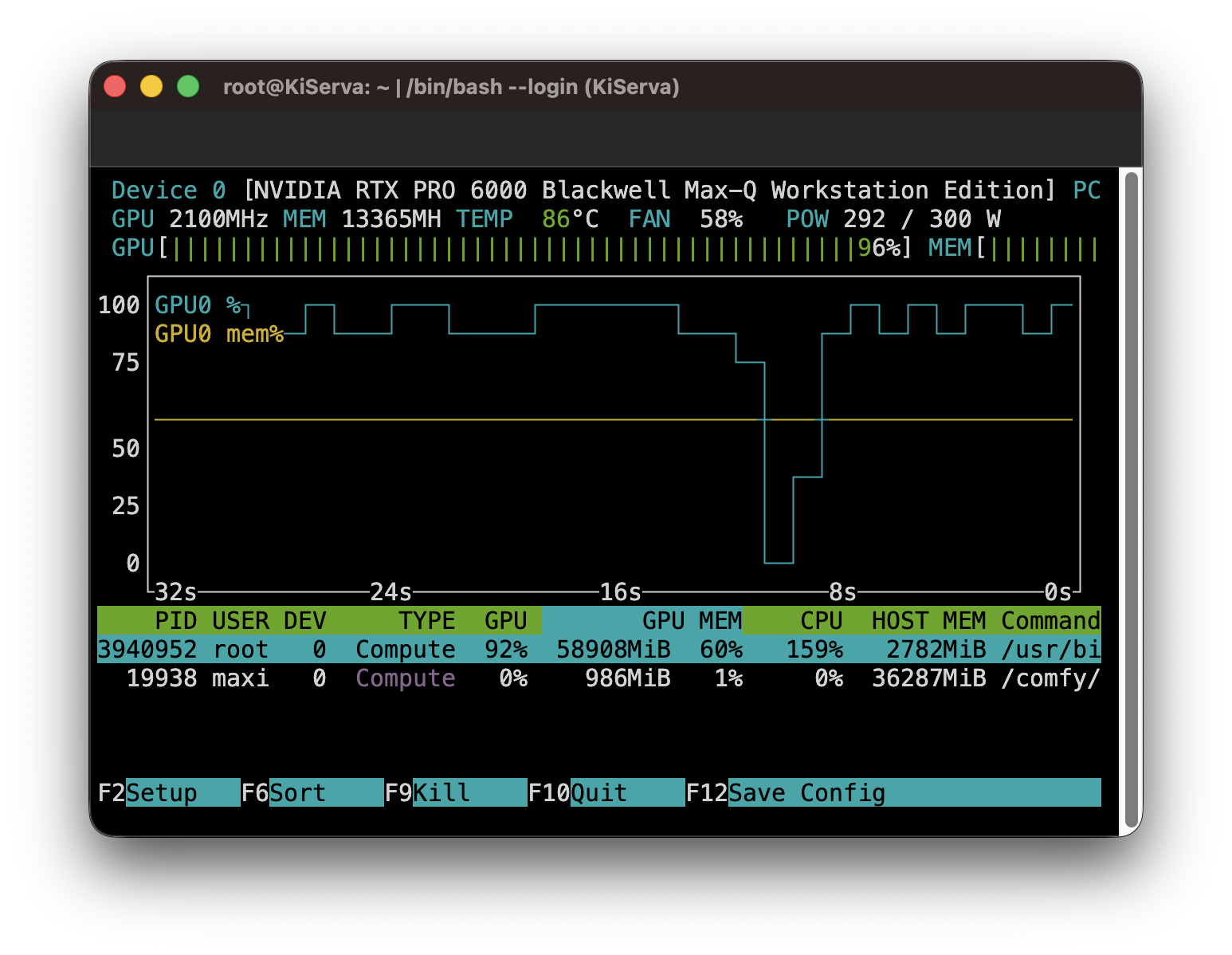
Ollama-Server
Variante 1: Ollama Installieren
Die Installation von Ollama im Terminal funktioniert sehr einfach:
curl -fsSL https://ollama.com/install.sh | shDanach kann der folgende Code ausgeführt werden, um den Server mit einem beliebigen Modell zu starten:
ollama launch qwen3-coderClaude Code arbeitet mit Modellnamen und Ollama erwartet ebenfalls einen Modellnamen, zum Beispiel:
qwen3-coder
qwen3.5
glm-4.7-flash
gpt-oss:20bFalls ein Tool einen klassischen Claude-Modellnamen erwartet, kann man in Ollama auch einen Alias anlegen. Die Ollama-Dokumentation zeigt dafür zum Beispiel:
ollama cp qwen3-coder claude-3-5-sonnetSomit kann ein Tool, das das Modell claude-3-5-sonnet erwartet, intern auf das lokale Modell qwen3-coder zeigen.
Wichtig ist bei den Modellen, eom Kontextfenster zu wählen, das groß genug ist. Denn Coding-Agenten brauchen viel Kontext: Dateien, Terminalausgaben, Fehlermeldungen, Diffs und Pläne landen schnell im Prompt. Ollama weist deshalb darauf hin, dass Claude Code ein großes Kontextfenster benötigt und empfiehlt mindestens 64k Tokens.
Je nach Modell kann die Kontextgröße über ein eigenes Modelfile konfiguriert werden, wie beispielsweise:
FROM qwen3-coder
PARAMETER num_ctx 65536Daraus kann man dann ein neues Modell erzeugen:
ollama create qwen3-coder-64k -f ModelfileUnd Claude Code damit starten:
claude --model qwen3-coder-64kAuch wenn es so wirkt, als ob Claude Code das Modell selber ausführt, wird mit dem Befehl oben lediglich Claude Code gestartet und angewiesen das Modell qwen3-coder-64k zu erwenden. Anstelle die Anthropic-API anzuspreche, kommuniziert Claude Code nun wegen der geänderten Variable ANTHROPIC_BASE_URL mit dem Ollama-Server, der dann das neue Modell bereitstellt.
Vairante 2: Ollama im Container
Als Alternative zum Installieren von Ollama, kann man auch einen Docker-Container starten:
docker run -d \
--name ollama \
-p 11434:11434 \
-v ollama:/root/.ollama \
ollama/ollamaDieser Befehl macht drei wichtige Dinge:
-p 11434:11434veröffentlicht die Ollama-API auf Host unter localhost:11434.-v ollama:/root/.ollamaspeichert Modelle persistent in einem Docker Volume namensollama. Ohne Volume wären heruntergeladene Modelle beim Entfernen des Containers weg.ollama/ollamagibt an, dass das offizielle Ollama-Docker-Image verwendet werden soll. Die offizielle Ollama-Dokumentation verwendet genau dieses Grundmuster mit Port11434und Volumeollama:/root/.ollama.
Da Ollama jetzt im Container läuft, werden Ollama-Befehle im Container ausgeführt:
docker exec -it ollama ollama pull qwen3-coder
docker exec -it ollama ollama run qwen3-coderNach dem Ausführen der Befehle kann Claude Code vom Host aus darauf zugreifen:
ANTHROPIC_AUTH_TOKEN=ollama \
ANTHROPIC_BASE_URL=http://localhost:11434 \
claude --model qwen3-coderDie wichtige Unterscheidung ist, dass die folgende Art von Befehl:
docker exec ... ollama pull/run/createModelle innerhalb des Ollama-Containers verwaltet.
claude --model ...startet Claude Code jedoch auf dem Host und lässt es über localhost:11434 mit Ollama sprechen.
Mit NVIDIA-GPU
Falls eine NVIDIA-GPU verwendet werden soll, brauchst man zusätzlich ein GPU-Passthrough. Der offizielle Ollama-Docker-Befehl sieht so aus:
docker run -d \
--gpus=all \
--name ollama \
-p 11434:11434 \
-v ollama:/root/.ollama \
ollama/ollamaDamit dieser Befehl funktioniert, muss auf dem Host das NVIDIA Container Toolkit eingerichtet sein. Ollama dokumentiert dafür ebenfalls --gpus=all.
Mit AMD-GPU
Für AMD-GPUs verwendet Ollama das rocm-Image von Ollama:
docker run -d \
--name ollama \
--device /dev/kfd \
--device /dev/dri \
-p 11434:11434 \
-v ollama:/root/.ollama \
ollama/ollama:rocmAuch dieses Muster ist in der offiziellen Ollama-Docker-Dokumentation beschrieben.